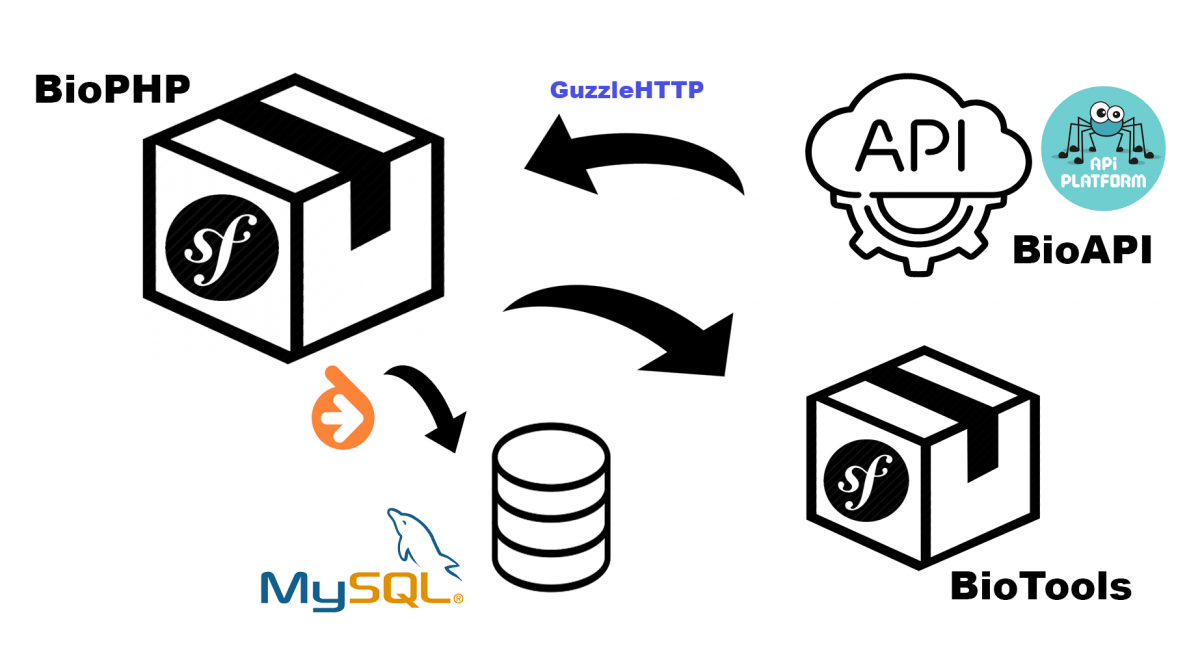
Vous avez dit Symfony 6.1? – Nicolas Grekas
Ici, un autre « core dev » de Symfony pour cette première conférence, qui nous rappelle qu’au sein même d’une même version majeure, il y a promesse de rétrocompatibilité … D’une version majeure à une autre, le chemin de migration continue. Il est conseillé de faire un composer update tous les mois; et tous les 6 mois, un composer update pour passer en version mineure suivante, pour corriger les dépréciations.
Il est déconseillé de commencer ou rester sur une version LTS, pour ne pas rester « lent » ou « stable ».
En 6.1 on a droit à :
– une modernisation du code via nouvelles syntaxes / fonctions
– une meilleure description des types natifs et génériques
– une simplification par abandon : SwiftMailer, Twig, FlexServer …
– une revisitation des classiques : composer runtime, symfony new (l’option –-full pour le website skeleton devient –website)
– des serveurs à longue durée d’exécutions
– une performance accrue.
Retour sur le nombre de PR : 6PR/jour en 12 mois soit 2000PR : 400 features, 700 bugs, +900 mineures)
Je vous laisse le loisir de regarder la rediffusion de la conférence pour avoir l’aperçu complet, et non exhaustif de cette mise à jour !
Mon avis : un bon tour de découverte de cette nouvelle version de SF, bien hâte de la tester en fait !
Code asynchrone dans une application Symfony synchrone – Jérôme Tamarelle
Petit rappel : Composer utilise depuis la version 2 des composants de ReactPHP, et peu de gens le savent.
Il est question de ces différents concepts :
1. I/O non bloquants
Fonctions natives de PHP pour les flux non-bloquants : stream_select, curl_multi_select, Symfony HTTPClient est non-bloquant.
2. Délégation de traitement à des processus parallèles
Effectuer des traitements en parallèle sans bloquer le processus courant, avec Sf Process ou encore Messenger
3. Branches de code concurrentes dans un même thread
Ici , on parle de promesses, coroutine, et fibers pour exécuter plusieurs branches de code en concurrence, sur le même thread.
A retenir :
– Une fonction synchrone peut appeler une fonction synchrone mais pas une fonction asynchrone.
– Une fonction asynchrone peut appeler une fonction synchrone et une fonction asynchrone.
Mon avis : je suis peu familiarisée avec ces concepts. Intéressant à découvrir par la pratique, peut-être avec un projet futur.
Développer une application web décentralisée avec Symfony et API Platform – Kevin Dunglas
SAUVONS LE WEB !!! DECENTRALISONS !!! Tel est le message de cette conférence de Dunglas, connu de tous pour être un des core devs de Api Platform.
Les GAFAM représentent 57% de tout le trafic mondial, la majorité de l’usage du web passe par ces quelques acteurs-là, et leur donne un contrôle quasi total des contenus des internautes. Ce qui était à des milliards de lieues de la volonté de Tim Berners-Lee quand il a crée le web ! Au départ il voulait vraiment créer un espace de libre expression pour les gens qui ne pouvaient pas le faire … le Web devait donner une voie aux personnes marginalisées, les autres médias étant réellement contrôlés, tous ceux qui avaient quelque chose à dire pouvaient le faire, via les URL, qui relient les sources les unes aux autres (on a donc un graphe de connaissances). Or les GAFAM donnent donc pas mal de problèmes de démocratie, vu qu’ils censurent à tout-va.
Aux origines, le Web 1.0, tout était décentralisé.
Puis le Web 2.0 (terme marketing) est arrivé, permettant aux utilisateurs de bénéficier des formulaires pour publier du contenu, créer des mixs de communautés. On a vu apparaitre les API web, ainsi qu’un mix d’acteurs non-commerciaux et commerciaux, ça se passait plutôt bien. Mais l’argent est entré en jeu.
Puis on voit naitre le Web 3, la promesse : re-décentraliser le web, casser le pouvoir des états surveillants. On propose d’utiliser la blockchain d’Ethereum et d’exécuter ce code sur les ordinateurs du réseau pour faire des sites web. Donc base sur les cryptomonnaies, trustless et permissionless. Sauf que des problèmes se posent : consommation énergétique (Ethereum toujours en POW), d’énormes structures américaines sont intéressées par le concept, chaine de Ponzi.
Donc, voici le concept du Web 3.0, apparu avec le web sémantique, crée par Tim Berners-Lee, qui consiste à utiliser le web comme immense base de données, le web est donc considéré comme base de connaissances, les opérations auraient une grande interopérabilité.
Pour cela on utilise un modèles de données abstrait pour représenter n’importe quel set de données : RDF. Mais on a d’autres formats : tableau HTML, N-Tuple dans un fichier texte, Turtle, JSON-LD.
Tim Berners-Lee présente son projet : SOLID. Les considérations physiques, politiques, etc … dont détaillées dans des documents émis en dur. Solid Toolkit permet de créer des application décentralisées et interopérables, la décentralisation des données personnelles, etc …
A mentionner qu’on peut construire une application Symfony avec Solid. Dunglas propose son bundle.
Mon avis : je suis TRES sensibilisée sur sujet, et j'avais envie, avant la pandémie de faire un gros projet lié au web, son évolution et sa centralisation, hélas remis à plus tard. L'idée est interessante et je vais me pencher sur le sujet, et regarder Solid d'un peu plus près ... mais toutefois, je me pose des questions. N'est-il pas mieux de sensibiliser les gens à faire leur propre site internet, comme avant ? et de créer l'arborescence de leur communauté à cet effet ? Leur faire comprendre ce qu'est le logiciel libre ? Si Dunglas passe par là, je serai ravie qu'il puisse répondre à mon interrogation ;) !
Mon avis global sur le séminaire
Une joie de retrouver tout ce beau monde et l’ambiance des séminaires sans entendre les mots maske aubligatouar, pace vaksinale et tout le toutim. J’aspire vraiment à retrouver la vie active d’avant que je menais sur ce point-là. Les différents stands étaient attractifs, et je suis bien contente d’avoir eu un beau t-shirt en cadeau, et un autre gagné sur le stand des Tilleuls.coop. Il faut juste que je pense la prochaine fois à imprimer mon badge avant de venir ! Les thèmes des conférences étaient variées, et la plupart étaient bien intéressantes et donnent envie de creuser le sujet abordé.
Sinon … gros bémol pour les déjeuners. J’adorais le concept du buffet proposé lors de ma dernière venue, qui permettait un éventail varié. Je fais très attention à ce que je mange, surtout quand je ne trouve pas le temps de faire du sport, que je mange au resto le soir avec ma chérie + les copains que je n’ai pas revus depuis un bail, et que j’ai de gros problèmes avec certains aliments (comme le fromage). Là c’était vraiment bourratif, trop riche et pas varié (sérieux les gars, un gâteau au Daim ? Pas un seul fruit !). Le souci c’est que le tarif du SfLive est plutôt conséquent, et pour moi chaque centime compte, la nourriture en fait partie. Et qu’on ne me parle pas de « raisons sanitaires », vu qu’on reste toujours tous mélangés dans les différentes salles … mais bon, on va me répondre qu’on n’a pas eu le choix, c’est ça ou rien … Oui, je suis exigeante 😀 !