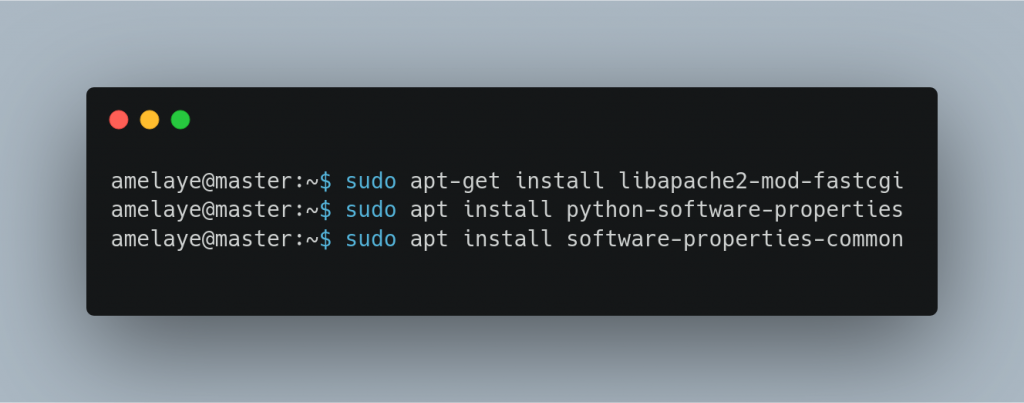
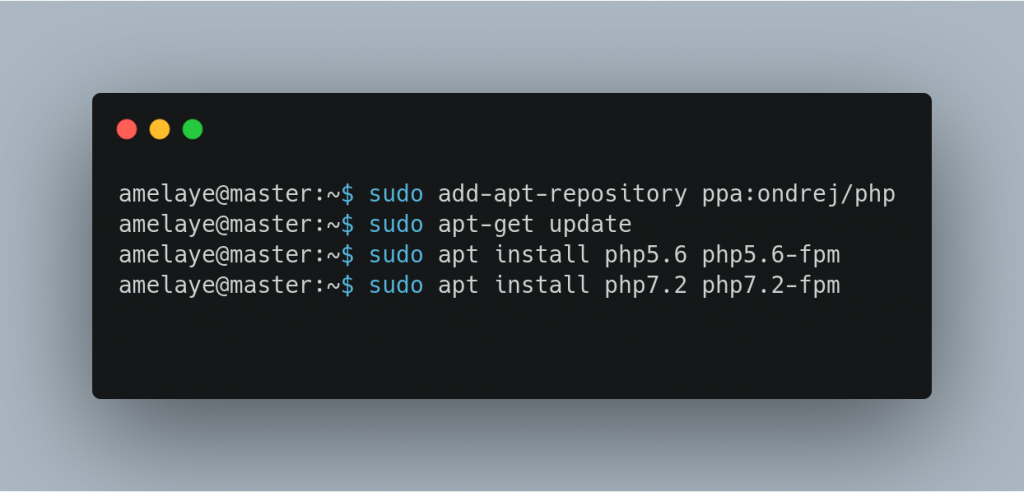
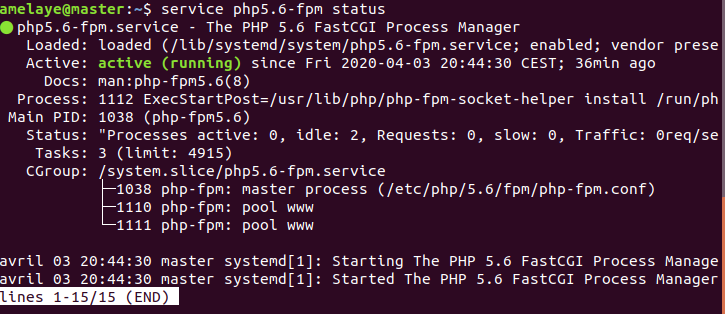
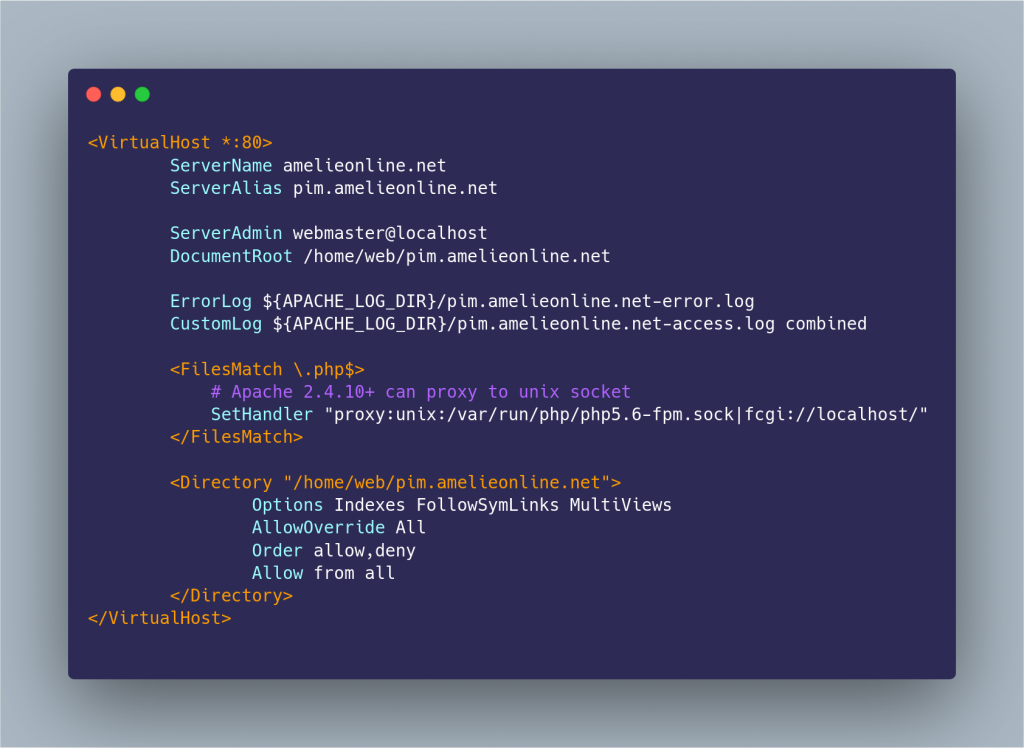
Aujourd’hui, pour changer, je vous parlerai de … front-end ! Bien que plus dévolue back, j’avais envie de faire d’une pierre deux-coups et de réaliser un joli mapping de mon monde Minetest.
Avec Minetest, c’est assez facile de générer des fichiers image qui retracent en 2D l’univers généré dans le jeu, avec minetestmapper. A partir de là, les plus créatifs peuvent s’amuser.
Pour la petite histoire, je suis en fait tombée sur le plan interactif du serveur Minetest LinuxForks, qui est juste splendide, et j’ai eu vraiment envie de me lancer ce défi.
Au commencement, une map qui rame à mort !
Du coup, j’ai intégré ce fichier dans une carte de base. Le code est simple, j’intègre Leaflet.js dans ma page web, et j’y intègre quelques markers. La bibliothèque, je la connaissais déjà, car je l’avais déjà intégrée pour l’outil d’un de mes clients BTP, pour y localiser les chantiers en cours. Mais Leaflet, c’est vraiment l’outil qui permet de créer des cartes, sans forcément qu’elle soit « terrestre », une « mappemonde ». Donc pas mal privilégiée par les geeks gamers.
Voilà grosso modo le code de base du premier jet que j’ai intégré dans mon index (j’y ai intégré après un div vide appelé map, bien entendu):
var map = L.map('map', { crs: L.CRS.Simple, center: [500, 500], scale: function (zoom) { return Math.pow(2, zoom); }, zoom: function (scale) { return Math.log(scale / 256) / Math.LN2; }, }); var bounds = [[0,0], [2000,2000]]; var image = L.imageOverlay('map.png', bounds).addTo(map); // Spawn var spawn = L.latLng([971.5, 1156.5]); L.marker(spawn).addTo(map).bindTooltip('Spawn Station', {sticky: false, direction: 'top'}); // Maison de Jym var jymHome = L.latLng([972, 1137]); L.marker(jymHome).addTo(map).bindTooltip('Maison de Jym', {sticky: false, direction: 'top'}); map.setView( [971.5, 1156.5], 3);
C’est déjà pas mal. La définition de la map en crs permet de générer une map personnalisable, le niveau de zoom est correct, on peut naviguer pépère. Sauf que la carte, qui est grande, met pas mal de secondes à charger, c’est lourd, très lourd. Et ça, c’est un gros souci. Sans compter que la map devient floue à un certain niveau de zoom avancé. A revoir, donc !
Le tiling, solution miracle !
Et puis j’apprends que Leaflet intègre très bien des briques d’images. A la base, on peut sans souci utiliser un coup d’imagemagick pour ce faire et recoller les morceaux, chose que la bibliothèque fait très bien. Donc pile ce dont j’ai besoin !
Pour créer les briques, il y a un script existant qui gère Leaflet. Il est en Python et s’appelle gdal2tiles-leaflet. Ne pas oublier avant de faire un petit sudo apt install python-gdal (pour les utilisateurs d’Ubuntu) et éventuellement installer python si ce n’est déjà fait, juste avant de l’utiliser.
Voici la commande que j’ai lancée :./gdal2tiles.py -l -p raster -z 0-10 -w none ../map.png ../tiles
Et j’ai attendu quelques bonnes minutes pour que toutes les briques soient générées. C’est un peu long mais ça vaut le coup. Ne pas oublier l’option -p raster car on en aura besoin par la suite, et surtout l’option -l qui définit spécialement des briques adaptées pour leaflet. J’ai demandé un niveau de zoom variable de 0 à 10, pour bien pouvoir avoir chaque détail de ma carte.
Gérer le tiling dans Leaflet
Maintenant qu’on a généré les briques, il faut pouvoir les assembler. Là encore, après pas mal de recherches, j’ai pu trouver de quoi satisfaire ma faim.
Bien avant, il faut intégrer la librairie rastercoords, pour pouvoir faire la correspondance des briques au format « raster » (l’option que nous avions vu plus haut). Et ainsi, avec ce code, vous pouvez déjà disposer d’une map sympa :
;(function (window) { function init (mapid) { var minZoom = 0 var maxZoom = 9 var img = [ 38192, // original width of image 29792 // original height of image ] // create the map var map = L.map(mapid, { minZoom: minZoom, maxZoom: maxZoom }) var rc = new L.RasterCoords(map, img) map.setView(rc.unproject([22000, 15450]), 9) L.control.layers({}, { //@todo }).addTo(map) L.tileLayer('./tiles/{z}/{x}/{y}.png', { noWrap: true, attribution: 'Creation Amelie DUVERNET aka Amelaye <a href="http://minetest.amelieonline.net">Projet Amelaye In Minerland</a>' }).addTo(map) } init('map') }(window))
Des markers jolis et dynamiques
Nous avons la carte, il faut maintenant y ajouter les markers. Pour ce faire, vous avez besoin de :
– La librairie font-awesome (on en a besoin pour extra-markers)
– La librairie leaflet-extra-markers
J’ai crée deux fonctions, la première, layerGeo qui permet de récupérer les points définis dans mon fichier geojson.js
function layerGeo (map, rc) { var layerGeo = L.geoJson(window.geoInfo, { // correctly map the geojson coordinates on the image coordsToLatLng: function (coords) { return rc.unproject(coords) }, // add a popup content to the marker onEachFeature: function (feature, layer) { if (feature.properties && feature.properties.name) { layer.bindPopup(feature.properties.name) } }, pointToLayer: function (feature, latlng) { return L.marker(latlng, { icon: feature.properties.id }) } }) map.addLayer(layerGeo) return layerGeo }
Ainsi qu’une autre, qui permet de trouver les « frontières » de la carte, et également d’afficher les coordonnées d’un emplacement au hasard cliqué :
function layerBounds (map, rc, img) { // set marker at the image bound edges var layerBounds = L.layerGroup([ L.marker(rc.unproject([0, 0])).bindPopup('[0,0]'), L.marker(rc.unproject(img)).bindPopup(JSON.stringify(img)) ]) map.addLayer(layerBounds) // set markers on click events in the map map.on('click', function (event) { // to obtain raster coordinates from the map use `project` var coord = rc.project(event.latlng) // to set a marker, ... in raster coordinates in the map use `unproject` var marker = L.marker(rc.unproject(coord)).addTo(layerBounds) marker.bindPopup('[' + Math.floor(coord.x) + ',' + Math.floor(coord.y) + ']').openPopup() }) return layerBounds }
Du coup, on revient sur notre code qui affiche la map et on corrige la ligne L.control.layers pour appeler nos fonctions :
L.control.layers({}, { 'Bounds': layerBounds(map, rc, img), 'Info': layerGeo(map, rc) }).addTo(map)
Maintenant passons aux choses sérieuses, la définition de nos coordonnées. Et là, on va passer nos jolis markers, ainsi que les points qui nous intéressent, et tout ceci va se passer au niveau d’un nouveau fichier geojson.js :
;(function (window) { // Markers var spawnStation = L.ExtraMarkers.icon({ icon: 'fa-anchor', markerColor: 'red', shape: 'star', prefix: 'fa' }); var metroStation = L.ExtraMarkers.icon({ icon: 'fa-subway', markerColor: 'blue', shape: 'circle', prefix: 'fa' }); var castle = L.ExtraMarkers.icon({ icon: 'fa-dungeon', markerColor: 'violet', shape: 'square', prefix: 'fa' }); // etc ... // geoJson definitions window.geoInfo = [ { 'type': 'Feature', 'properties': { 'name': 'Spawn Station', 'id': spawnStation }, 'geometry': { 'type': 'Point', 'coordinates': [22087, 15321] } }, // Castles { 'type': 'Feature', 'properties': { 'name': 'Chateau dans le ciel', 'id': castle }, 'geometry': { 'type': 'Point', 'coordinates': [22088,14112] } }, { 'type': 'Feature', 'properties': { 'name': 'Chateau Royal', 'id': castle }, 'geometry': { 'type': 'Point', 'coordinates': [22229,15299] } }, { 'type': 'Feature', 'properties': { 'name': 'Chateau Amelaye', 'id': castle }, 'geometry': { 'type': 'Point', 'coordinates': [22060,15402] } }, // etc ... ] }(window))
Là, j’ai pas mal galéré car il faut injecter les markers personnalisés dans un fichier qui doit être scrupuleusement rigoureux, car geojson est une norme. J’ai donc passé les variables qui correspondent à la définition des « templates de markers » dans la propriété id. C’est caduque, bricolé, mais ça marche.
Et voilà le résultat (disponible en ligne) :
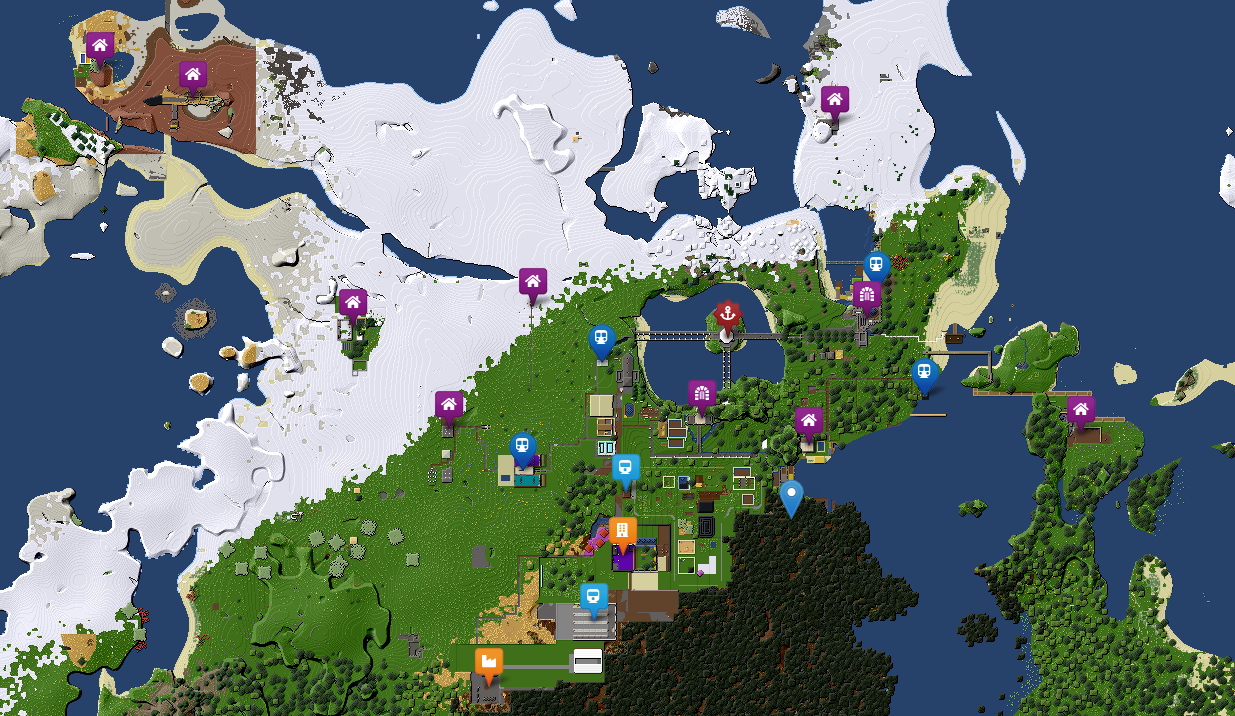
Nous voici maintenant avec une map rapide à charger, qui intègre pas mal de points personnalisables. Il reste pas mal de choses à faire, j’ai bien envie d’utiliser une base de données pour créer une API, voire une base ElasticSearch qui se chargera de générer le fichier geojson, mais pour l’instant je n’ai pas décidé de la suite. Qu’en pensez-vous ?
Voici pour plus de détails le rendu final sur mon Github.