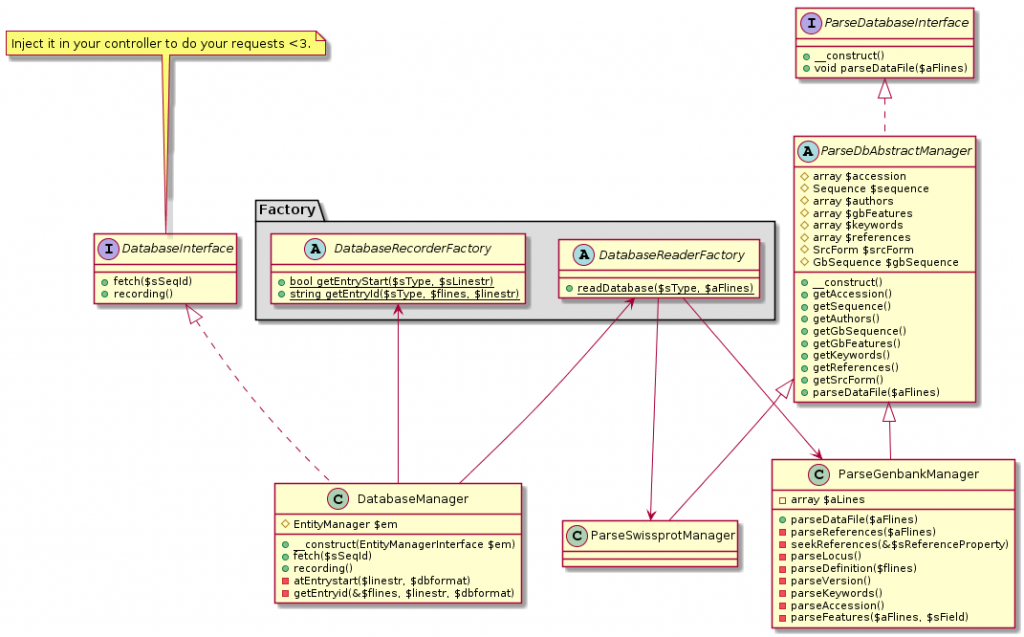
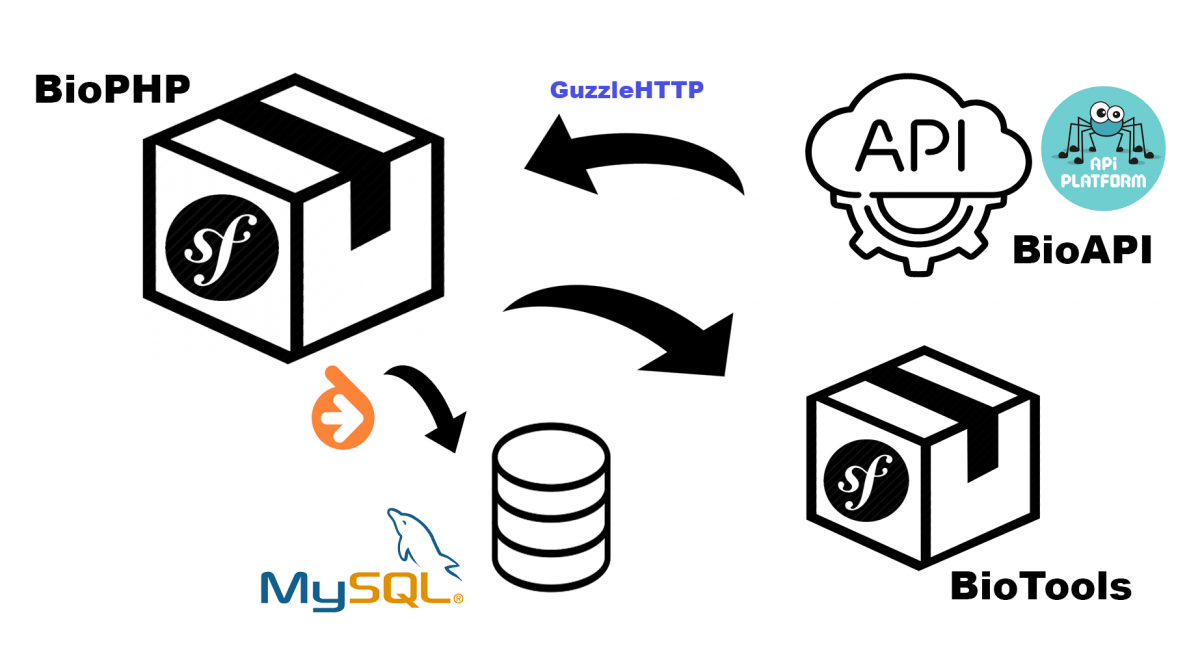
Il y a quelques jours je suis tombée sur cet article, réponse à un tout autre billet de blog que j’avais plutôt trouvé pertinent.
J’ai été à la fois dev et lead dev. J’ai pu me confronter à des problématiques de gestion d’équipe dans une structure où il y avait quelques soucis qui ne dépendaient pas de moi, et ça retraçait assez fidèlement ce qu’une boite doit faire pour garder une bonne équipe. Ce n’est pas uniquement une affaire de garder un dev, mais garder une vraie équipe soudée et productive dans la satisfaction. A mes yeux, une boite qui comprend ces points a un gage de qualité. Mais passons, ce n’est pas le sujet. Le sujet a été une seule phrase, tellement absurde que je n’ai pu m’empêcher de la twitter : « Twitter a démarré avec Ruby; Facebook avec PHP ; deux technologies bien pourries et so OK Boomer aujourd’hui. » (sic).

Déjà, ça manque d’argument, pourquoi « pourries », et puis ce « ok boomer » tellement dénué de sens …
Je n’ai pas d’affinité particulière avec Ruby, j’ai déjà bidouillé avec Ruby On Rails, que j’ai trouvé pas mal … mais sans plus.
Pour moi PHP représente tout la dynamique du web, et pour preuve, c’est le rare qui tienne encore debout et qui ait autant de popularité depuis 25 ans. Je ne parlerai pas de Go, qui a sa côte de popularité, mais tout frais, ou de Javascript qui a engendré NodeJS qui pour moi est plus une mode. Javascript n’a son intérêt qu’en front-end, à mes yeux.
Au commencement … il y avait … juste du script pour page HTML en fait …
Je me suis mise en premier à PHP car c’était à mes yeux celui qui allait pérenniser, j’ai eu comme une intuition qui me disait de foncer dedans. Car ce n’était pas gagné, au début des années 2000, les entreprises préféraient embaucher des développeurs ASP ou J2EE pour leur back-end et applications web. Fraîchement sortie des bancs de fac, je ne pouvais pas payer et investir pour apprendre ASP sur un serveur dédié, alors que PHP est disponible gratuitement.
Je passe cette discussion avec le « petit Gregory du Japon » (il se reconnaîtra) qui m’avait balancé en 2000 : « si tu fais un jour du PHP je me ferai nonne. Oui, tu as bien lu : NONNE ». Challenge accepted. J’attends toujours que tu mettes le voile, Greg.
Donc j’ai continué à me pencher sur le vilain petit canard, ce PHP qui pouvait « additionner des salades avec des macaronis ». Et il suffit de regarder du code legacy pour se rendre compte de ses faiblesses … le PHP 4 objet avec ses constructeurs spéciaux (car le langage n’avait pas au départ été conçu pour le modèle objet), il fallait parfois réinventer la roue pour faire des itérateurs, ses noms de fonctions natives à la one-again (on a str_getcsv et puis après strchr, un coup underscore, un coup pas, logique les gars ?) et surtout son faible typage (toujours d’actualité mais en voie de progrès. Mais n’est-ce pas un bon point, aussi ?). Mais PHP était un langage facile à apprendre, et il l’est toujours : pour ceux qui veulent se faire la main en programmation, c’est un bon début.
Le souci de qualité
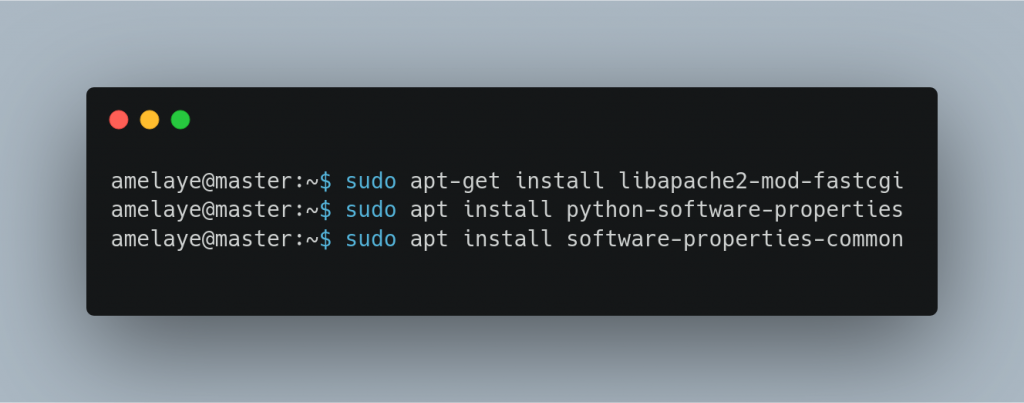
Pourtant 25 ans après, PHP est on ne peut plus présent, ASP ne fait plus parler de lui et J2EE se raréfie. Il est même devenu plus costaud qu’avant … son modèle objet se peaufine, le typage se fait de plus en plus strict, et puis les librairies évoluent de plus en plus notamment avec l’apparition de SPL, mais également des librairies. Vanilla PHP n’est plus trop d’actualité, on a vu apparaître PECL, PEAR, et aujourd’hui la star c’est Composer, qui permet d’installer à la volée bon nombre de bibliothèques, et d’analyseurs syntaxiques. Car le développeur PHP d’aujourd’hui est soucieux de la qualité de son code : il fait appel à des analyseurs (notamment PHP-Stan) et produit des tests unitaires et des tests fonctionnels (Behat …).
La puissance des frameworks et des design patterns

La force de PHP, après avoir proposé moult CMS tels que SPIP, Joomla … dans les années 2000, a résidé dans l’apparition des frameworks, qui ont solidifié les bases du langage pour permettre non seulement aux devs de coder plus proprement, mais également de pouvoir définir des architectures évoluées en fonction des design patterns (ce qui fait de plus en plus penser à une structure type JAVA) : Zend Framework, Symfony et Laravel en tête de liste. Des architectures qui évoluent et peuvent solliciter efficacement des API REST pour permettre une mobilité des données, segmenter le code en multi-repositories pour permettre une meilleure maintenabilité du code. Et par ce biais, a permis aux CMS d’évoluer, on pense à Drupal ou Prestashop qui ont intégré Symfony dans leur code.
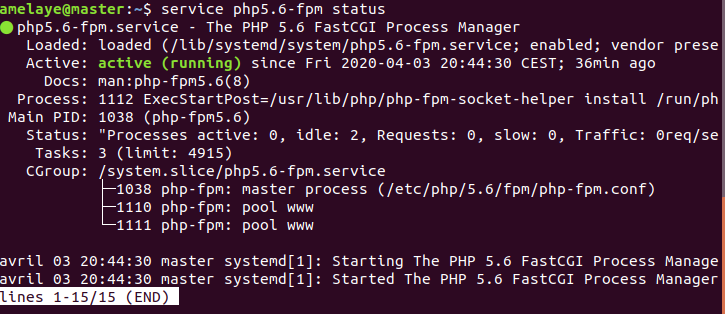
PHP a également gagné en performance et scalabilité grâce à FPM, qui permet de pouvoir lancer plusieurs versions du serveur. Et by the way, Facebook utilise toujours PHP … en sous-marin mais toujours …
Toujours en évolution !
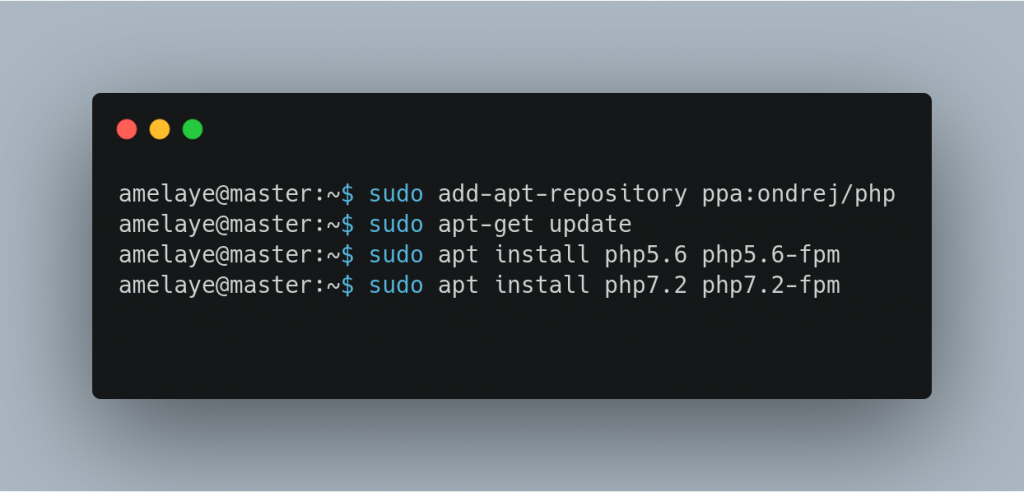
A ce jour, PHP 8 est en prévision, avec plein d’améliorations, notamment le Just In Time. Et j’avoue avoir bien reçu PHP 7.4, car je l’avais attendue longtemps depuis des années, cette feature : PHP 7.4 intègre les déclarations de type d’argument. Enfin on peut typer les propriétés d’une classe !!! Yes we can ! Yalla !
Aujourd’hui PHP est devenu plus qu’un simple outil de scriptage pour sites web :
– il permet de réaliser des scripts en ligne de commandes et tâches automatisées, et on peut même créer des exécutables !
– il permet de programmer de vraies applications web
– il permet efficacement de se connecter avec une base de données, de manière de plus en plus sécurisée via les requêtes préparées
Il est PARTOUT, et même Microsoft, qui avait lancé ASP, le soutient dans les séminaires. Les débutants peuvent facilement l’appréhender en manipulant progressivement leurs pages HTML, et en guise de cerise sur le gâteau, la communauté des développeurs PHP est LARGE, depuis toujours. Vous séchez ? Vous avez obligatoirement des forums, des sites, la doc officielle régulièrement mise à jour, des Slacks pour vous aiguiller. Et il reste open-source et gratuit !
Alors sérieusement, PHP, un langage pourri et OK Boomer ?